자격증 공부/SQLD
SQLD 2. 데이터 모델링과 성능
XZXXZX
2021. 9. 2. 19:12
728x90
반응형
https://sy-log.tistory.com/62?category=992908
[1] 정규화 (Normalization)
(1) 정규화 - 데이터를 분해하고, 중복을 제거하여, 데이터 모델의 독립성을 확보하는 과정
- 이상현상 존재하는 모델 -> 정규화 모델

- 정규화(Normalization)
- 데이터의 일관성, 최소한의 중복, 최대한의 유연성을 위한 방법
- 이상현상이 존재하는 모델: 새로운 데이터를 추가할 때, 불필요한 정보를 같이 추가하거나, 아예 추가할 수 없는 문제 발생
- 정규화된 모델 : 테이블 분해 -> 중복 데이터 제거됨
- 분해된 테이블은 Join 연산을 통해 합집합으로 통합 가능
- 비즈니스 변화가 생겨도, 데이터 모델의 변경을 최소화할 수 있음
- 제 1~5 정규화 가능함/ 실질적으로는 제 3 정규화까지만 수행
- 정규화 절차 : 제 1 정규화 - 제 2 정규화 - 제 3 정규화 - BCNF - 제 4 정규화 - 제 5 정규화
- 제 1 정규화
- 속성 원자성 확보
- 기본키 설정 - 제 2 정규화
- 기본키가 속성 2개 이상
- 부분 함수 종속성 제거 - 제 3 정규화
- 기본키 외 컬럼 간 종속성 제거
- 이행 함수 종속성 제거 - BCNF
- 후보키가 기본키를 종속시키면 분해함 - 제 4 정규화
- 여러컬럼이 한컬럼을 종속시키면
- 다중 값 종속성 제거 - 제 5 정규화
- 조인에 의해서 종속성 발생하면 분해함
- 제 1 정규화
(2) 함수적 종속성 - X->Y 이면, Y는 X에 함수적으로 종속 = X가 변화하면 Y도 변화
- 제 1 정규화 (1NF) - 나머지 컬럼들을 함수적으로 종속하는 "기본키"를 설정

- "학번" 하나 혹은 "학생ID" 하나만으로 유일성을 만족하지 못하는 경우라고 가정함.
- 따라서 "학번"과 "학생ID" 2개의 컬럼을 기본키로 설정.
- 제 2 정규화 (2NF) - 기본키가 2개 이상의 칼럼으로 이루어진 경우, 부분 함수 종속성을 제거

- 부분 함수 종속성: 기본키가 2개 이상인 경우에만 발생.
- "학생 ID" 하나가 "이름" 하나만 함수적으로 종속.

- "학생" 테이블로 분해하여, 새로운 테이블을 도출.
- "학생" 테이블의 기본키를 "학생ID"로 설정.
- 부분 함수 종속성을 제거함
- 제 3 정규화 (3NF) - 제 1, 제 2 정규화를 수행한 다음, 이행 함수 종속성을 제거
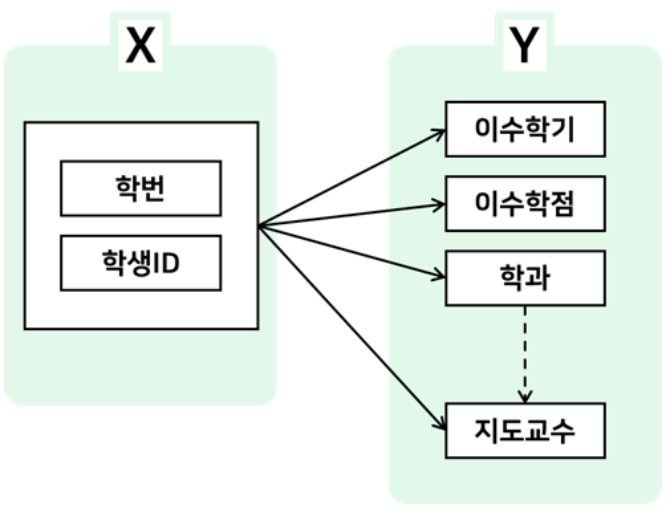
- 이행 함수 종속성 : 기본키 외 다른 컬럼 간에 종속성 발생.
- "지도교수"가 "학과"에 함수적으로 종속.

- "지도교수" 테이블로 분해하여, 새로운 테이블을 도출.
- "지도교수" 테이블의 기본키를 "학과"로 설정
- 이행 함수 종속성을 제거함
- BCNF (Boyce-Codd Normal Form) - 복수의 후보키 & 복합속성 후보키 & 서로 중첩되는 경우

- 복수의 후보키가 나머지 컬럼을 함수적으로 종속
- 기본키("학번", "과목번호")가 "교수"를 종속.
- "교수"가 후보키이고 "과목번호"를 함수적으로 종속. ("교수"가 최소성, 유일성을 만족하여 후보키로 인식됨)
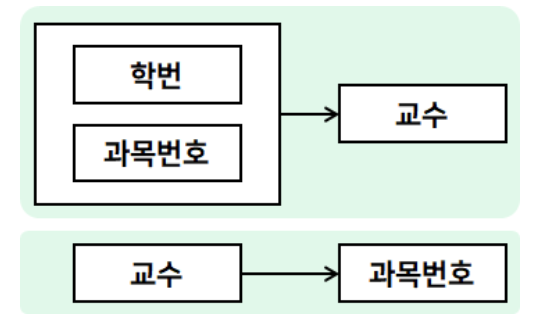
- "교수" 테이블로 분해하여, 새로운 테이블을 도출
- "교수" 테이블의 기본키는 "교수"로 설정
- "과목번호"는 "교수" 테이블의 속성이 됨.
[2] 정규화와 성능
(1) 정규화의 문제점
- 정규화의 문제점 : 조인 & 성능저하 유발
- 데이터 조회 시 조인(Join)을 유발함
- CPU, 메모리를 많이 사용함
- 정규화는 조인을, 조인은 부하를 유발함
- ex. "직원"과 "부서"테이블에서 "부서코드"가 같은 행을 찾는 경우
- 중첩된 루프 = 이중 for문을 사용해야함
- 데이터양 증가하면, 비교 건수도 증가함
- 정규화의 문제 해결 방법
- 인덱스, 옵티마이저를 통해 비효율 해결
- 조인에 의한 성능 저하를 해결하기 위해 반정규화를 하여, 하나의 테이블에 저장
- 반정규화 : 데이터 중복을 허용
- 컬럼이 계속 증가하여, 조인이 최소화 됨
- 조인 감소하면, 조회 빠르게 할 수 있음
- 반정규화의 문제점
- 반정규화는 데이터를 중복시키므로 또 다른 문제점을 발생시킴
- 너무 많은 컬럼이 추가되면, 1개 행의 크기가 너무 커짐
- DB 관리시스템의 입출력 단위인 블록 크기(Block Size)를 초과함
- 1개 행을 읽기위해 여러 블록을 읽어야함 -> 디스크 입출력 증가 -> 성능 저하 유발
- 반정규화 수행 : 트랜잭션 유형 및 용량 등을 분석하고, 정규화를 수행한 후에, 반정규화를 수행해야 한다.(병렬처리 X)
=> 트랜잭션 유형과 데이터 용량 등을 고려해보고, 성능 이슈가 특별히 없다면 반정규화를 하지 않아도 된다. - 반정규화를 수행하면 정규화된 모델보다 조회속도가 항상 빨라지는 것이 아니다.
- 반정규화를 통해 하나의 테이블에 컬럼 개수가 많아지면, 조인 개수는 감소한다.
- 그러나 테이블 행의 길이가 길어지면서, 입출력 단위보다 길어질 수도 있다.
- 이러한 경우, 하나의 행을 조회할 때 입출력을 여러 번 하면서 성능이 떨어질 수 있다.
[3] 반정규화 (De-Normalization)
(1) 반정규화 - 데이터베이스 성능 향상을 위하여, 데이터 중복을 허용하고 조인을 줄이는 방법
(2) 반정규화를 수행하는 경우
- 정규화에 충실하면 종속성&활용성을 향상되지만, 수행속도가 느려지는 경우
- 다량 범위를 자주 처리하는 경우
- 특정 범위만 자주 처리하는 경우
- 요약/집계 정보가 자주 요구되는 경우
- 반정규화 절차 : 대사 조사 및 검토 - 다른 방법 검토 - 반정규화 수행
- 대상 조사 및 검토 - 데이터 처리범위, 통계성 등을 확인
- 다른 방법 검토 - 클러스터링, 뷰, 인덱스 튜닝 등을 검토
- 반정규화 수행 - 테이블, 속성, 관계 등을 반정규화
- 반정규화 기법: 계산된 컬럼 추가/ 테이블 수직분할/ 테이블 수평분할/ 테이블 병합
- 계산된 컬럼을 추가함
- ex. 총판매액, 평균잔고 등
- 필요한 값을 미리 계산하여 특정 컬럼에 추가함 - 테이블 수직분할
- 한 테이블에서 컬럼 분할
- 두개 이상의 테이블로 분할 - 테이블 수평분할
- 값을 기준으로 테이블 분할
- (한 테이블에서 행 분할) - 테이블 병합
- 1 대 1 관계를 하나로 병합
- 1대 N 관계의 테이블을 병합
- 슈퍼-서브 타입 관계를 병합
- 계산된 컬럼을 추가함
- 파티션 기법(Partition) : 테이블 분할 방법 중 하나
- 파티션을 사용하여 테이블을 분할하면
- 논리적으로는 하나의 테이블이지만
- 물리적으로는 여러 개의 데이터 파일에 분산 저장된다.
- 파티션 기법 장점
- 데이터 조회 시, 액세스 범위 감소 -> 성능 향상
- 분할되어 있기 떄문에, Input/Output 성능 향상
- 각 파티션을 독립적으로 백업&복구 가능
- 파티션 기법 종류
- Range Partition : 데이터 값 범위를 기준으로 파티션
- List Partition : 특정값을 지정하여 파티션
- Hash Partition : 해시 함수를 적용하여 파티션
- Composite Partition : 범위 + 해시를 복합적으로 사용함
- 테이블 병합
- 1 대 1 관계의 테이블 -> 테이블 1개로 병합
- 1 대 N 관계의 테이블 -> 병합으로 성능은 올릴 수 있지만, 데이터 중복이 다량 발생함
- 슈퍼타입과 서브타입 관계가 발생하면 -> 테이블 통합으로 성능 향상시킴
- 슈퍼타입 - 서브타입은 부모-자식 관계

- 배타적 관계와 포괄적 관계
- 배타적 관계
- SuperType이 Sub1 이거나, Sub2 인 경우
- ex. "고객"이 "개인고객"이거나 "법인고객"인 경우 - 포괄적 관계
- SuperType이 Sub1 일 수도 있고, Sub2 일 수도 있는 경우
- ex. "고객"이 "개인고객"일 수도, "법인고객"일 수도 있음
- 배타적 관계
- 슈퍼타입 및 서브타입 변환 방법
- OneToOne Type
- 슈퍼타입, 서브타입을 개별 테이블로 도출함
- 테이블 개수가 많음
- 조인 다수 발생
- 관리 어려움 - Plus Type
- 슈퍼타입과 서브타입 테이블로 도출
- 조인 발생
- 관리 어려움 - Single Type
- 슈퍼타입, 서브타입을 하나의 테이블로 도출함
- 조인 성능 좋음
- 관리 편리함
- 입출력 성능 나쁨↓
- OneToOne Type
[4] 분산 데이터 베이스

(1) 분산 데이터베이스 - 분산된 작업 처리를 수행하여, 투명성을 제공하는 데이터베이스
- 중앙 집중형 데이터베이스 : 1대의 물리적 시스템에 DB 관리 시스템을 설치 -> 여러 사용자가 시스템에 접속하여 사용
- 분산 데이터베이스 : 물리적으로 떨어진 DB에 네트워크로 연결 -> 단일 DB 이미지를 보여주고 분산된 작업처리 수행
- 네트워크로 분산되어 있음
- 지역 DB를 독립적으로 관리
- 동일한 관리 시스템 : 분산 DB 구축이 어렵지 않음
- 여러 종류의 관리 시스템 : 이기종 DB 관리 시스템으로 연동 -> DB 미들웨어(ODBC, JDBC)를 사용해야함- 분산 데이터 베이스 장점
- 신뢰성 & 가용성 높음
- 병렬처리 수행 -> 빠른응답 가능
- 시스템 용량 확장 쉬움 - 분산 데이터베이스 단점
- 보안 & 관리 & 통제 어려움
- 데이터 무결성 관리 어려움
- 데이터베이스 설계 복잡
- 분산 데이터 베이스 장점
- 분산 데이터베이스의 투명성 종류 : 분할 투명성/ 위치 투명성/ 지역 사상 투명성/ 중복 투명성/ 장애 투명성/ 병행 투명성
- 분할 투명성
- 각 단편의 사본이 여러 시스템에 저장되어 있음을 인식할 필요 없음 - 위치 투명성
- 고객이 사용하려는 데이터의 저장 장소를 명시할 필요 없음 - 지역 사상 투명성
- 각 지역 시스템의 이름과 무관한 이름을 사용가능 - 중복 투명성
- 객체가 여러 시스템에 중복되어 존재해도, 데이터의 일관성이 유지됨. - 장애 투명성
- 각 지역 시스템 혹은 통신망이 이상이 생겨도, 데이터의 무결성이 보장됨 - 병행 투명성
- 여러 고객이 동시에 트랜잭션을 수행해도, 결과에 이상 없음
- 분할 투명성
(2) 분산 데이터베이스 설계방식 - 상향식 & 하향식
- 상향식 설계 방식
- 지역 스키마 작성후 -> 전역 스키마 작성
- 지역별로 데이터베이스를 구축한 후에 전역 스키마로 통합한다. - 하향식 설계방식
- 전역 스키마 작성 후 -> 지역 스키마 작성
- 전사 데이터 모델(기업 전체)을 수렴하여 전역 스키마 생성, 그 다음에 각 지역별로 지역 스키마를 생성한다.
728x90
반응형